
CONSERVATOIRE NATIONAL DES ARTS ET METIERS
CENTRE REGIONAL ASSOCIE DE TOURS
Examen Probatoire pour l'obtention du
Diplôme d'Ingénieur du C.N.A.M.
SPECIALITE : ELECTRONIQUE.
Epreuve orale
Le 15 juin 1998.
-oOo-
Rodolphe BATTAULT
Sujet : La reconnaissance vocale,
techniques utilisées, applications actuelles et futures.
Jury : Président :
Madame le Professeur Claude FERNANDES, Professeur Responsable au CONSERVATOIRE NATIONAL DES ARTS ET METIERS de PARIS,
Professeur Principal :
Monsieur L. JONCHERAY, Professeur correspondant au C.R.A. au CONSERVATOIRE NATIONAL DES ARTS ET METIERS de TOURS,
Assistés de :
Monsieur C. BORDEAUX, Electronique B,
Monsieur J.C. WAUTERS, Composants électroniques B,
Enseignants au Centre Régional Associé au Conservatoire National des Arts et Métiers de Tours.
Sommaire
1. Introduction
2. Généralités
2.1. Reconnaître la parole, pour quoi faire ?
2.2. La petite histoire de la reconnaissance vocale
2.2.1. 1950, les débuts
2.2.2. Problèmes rencontrés durant ces années
2.2.2.1. Continuité
2.2.2.2. Variabilité
2.2.2.3. Reconnaissance des informations en fonction de la tâche à accomplir
2.2.3. Depuis 1970
2.2.3.1. L'approche globale
2.2.3.2. L'approche analytique
2.3. Le mécanisme de la parole
2.3.1. Les résonateurs
2.3.2. L'appareil phonatoire
2.4. L'information vocale
2.5. L'appareil auditif
2.5.1. L'aire d'audition
2.5.2. Echelles des hauteurs
2.5.2.1. L'échelle des Mels
2.5.2.2. L'échelle de Bark
3. Les méthodes de reconnaissance vocale
3.1. Technologie analogique : Le spectrographe
3.2. Technologie numérique, introduction
3.3. La reconnaissance globale
3.4. La reconnaissance analytique
3.5. Le prétraitement du signal
3.5.1. Acquisition et mise en forme du signal
3.5.2. L'analyse temps-fréquence du signal
3.5.2.1. L'analyse spectrale par Transformée de Fourier à Court Terme (TFCT)
3.5.2.2. L'analyse par prédiction linéaire (LPC)
3.5.2.3. L'analyse par évaluation des Coefficients Cepstraux
3.5.2.4. La représentation par formes d'ondes
3.5.2.5. L'analyse par ondelettes de Morlet
3.6. Les outils de comparaisons
3.6.1. La comparaison dynamique ou DTW
3.6.2. Les modèles de Markov cachés (HMM)
3.6.3. Le décodage acoustique phonétique
3.7. Les traitements linguistiques
4. Classification des systèmes par application
4.1. Les systèmes de commandes vocale
4.2. Les systèmes de compréhension
4.3. Les machines de dictée
5. Classification par type d'information recueillie
5.1. La reconnaissance de la parole proprement dite
5.1.1. Reconnaissance de mots isolés
5.1.2. Reconnaissance de mots enchaînés
5.1.3. Détection de mots
5.2. L'identification du locuteur
5.3. La vérification du locuteur
6. Les systèmes et technologies actuels
6.1. Les outils de développement
6.2. Les produits finis
7. Conclusion et perspectives d'avenir
SIGLES et ABREVIATIONS
GLOSSAIRE
BIBLIOGRAPHIE
Si l'homme a la faculté de comprendre un message vocal provenant d'un locuteur quelconque, dans des environnements souvent perturbés par le bruit, quelques soient son mode d'élocution, la syntaxe et le vocabulaire utilisés, la machine est-elle capable d'en faire autant ? Une solution peut-elle répondre en globalité à ces difficultés ? Le problème de la reconnaissance vocale est un sujet d'actualité et pour l'instant, seules les solutions partielles sont aptes à répondre aux différentes tâches que la machine doit effectuer.
Cette étude propose, compte tenu de l'ampleur du domaine, une synthèse non exhaustive des techniques utilisées en reconnaissance de la parole, ainsi que de leurs domaines d'application.
Cet ouvrage, bien qu'accentué par l'orientation de ma formation sur les principales techniques associées au prétraitement du signal de la parole, propose un état de l'art de la reconnaissance vocale. En effet, la lecture des différents paragraphes permettra de suivre le processus de génération de la parole jusqu'à sa reconnaissance. On y trouvera les domaines d'application, le mécanisme de production de la parole et les paramètres qui la caractérisent, les principes des techniques dominantes d'analyse du signal, les principales méthodes de discrimination et enfin, un bilan des produits actuels et les applications.
Pour que l'homme puisse communiquer avec la machine. Avec la parole, plus de regard rivé à un écran et de mains affairées sur un clavier. Grâce à la reconnaissance vocale, un homme, par exemple, peut se déplacer et se consacrer à sa tâche principale dans des secteurs comme :
L'industrie :
Commande de machines, conduite de processus, Routage ou tri d'objets (aéroports,...).
Programmation de machines-outils à commande numérique.
Entrée de données dans les systèmes de conception assistée par ordinateur (menu).
Contrôle de qualité et inspections des fabrications sur chaîne de montage.
La télématique :
Demande de renseignements, réservation, consultation de bases de données.
Numérotation téléphonique automatique (téléphones cellulaires,...).
La Bureautique :
Commande de fonctions, entrée de données, machine à écrire automatique.
L'aviation :
Commande d'appareillages, contrôle aérien automatique.
Les services et le commerce :
Consultation par entrée vocale, contrôle de gestion de stock, traduction simultanée.
La Sécurité et la Justice:
Empreinte vocale pour accès en zone réglementée (lieu, fichier,...).
Identification des suspects.
L'enseignement et la formation :
Formation des pilotes, programmation, enseignement assisté par ordinateur (langues,...).
L'aide au médecin :
Diagnostic assisté par ordinateur, choix de médicaments, comptes rendus.
Commande d'appareillages divers (chirurgie...).
Repérage des indices physiologiques (zézaiement, bégaiement,...) et psychologiques (émotivité, timidité, agressivité,...).
L'aide au patient :
Education de la voix des malentendants, commande vocale pour malades immobilisés.
Divers :
Les applications grand public concernent l'automobile (commande vocale d'équipements annexes tels que climatisation, essuie-glace, lève-vitres), le jouet (téléguidage vocal,...), les jeux électroniques et l'appareillage domestique (commande de téléviseur, lave-linge,...). [B2,B7,B11]
Les premiers travaux qui se relient directement à la reconnaissance automatique de la parole furent ceux de J.Dreyfus-Graf, en Suisse puis en France.
1949 : Visualisation sur un oscilloscope du signal de parole filtré dans six bandes de fréquence différentes.
1952 : Association d'un processus de décision automatique : le premier “ Phonétographe ” traduisait l'onde sonore en éléments phonétiques.
Aux USA, reconnaissance de chiffres isolés.
1956 : Système de distinction des voyelles pour différents locuteurs et première “ machine à écrire phonétiquement ”, dix syllabes par locuteur.
1960 : Utilisation des méthodes numériques.
1961 : Le phonétographe III était capable d'écrire, sous une dictée bien prononcée, toutes les lettres de l'alphabet.
1964 : Lors d'un salon, IBM effectue la première démonstration de dictée de chiffre grâce au logiciel de reconnaissance vocale “ Shoebox ”.
1965 : reconnaissance de phonèmes en parole continue.
1960 - 1970 : L'ordinateur recherche automatiquement des sons spécifiques et les met en mémoire pour référence ultérieure.
1970 : Utilisation des niveaux syntaxiques et sémantiques
[B1,B10,B11]
Contrairement au langage écrit, où les mots sont séparés par des “blancs” dans les textes manuscrits ou par des espaces dans les textes dactylographiés , les séparateurs, symbolisés par les silences entre les mots, sont parfois très difficiles à repérer.
Elle provient de la position d'un phonème par rapport aux autres (coarticulation), des locuteurs aux timbres différents : homme, femme, enfant et à leur mode d'élocution : voix chantée, criée, enrouée, sous stress,....Elle est due aussi à la qualité du moyen d'acquisition et du bruit environnemental.
La reconnaissance vocale peut s'effectuer sur les sons eux-mêmes, sur la structure syntaxique d'une phrase (dictée), sur la signification d'une phrase (robots) ou sur l'identité du locuteur et son état émotionnel (joyeux, en colère,...).
Les difficultés rencontrées durant ces débuts ont amené les scientifiques à classifier, puis à déterminer des axes de recherches suivant le tableau 1. [B8,B11]
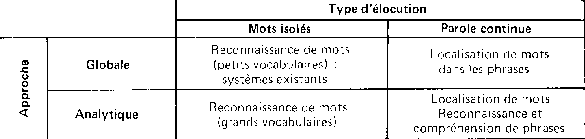
Tableau 1 : Les problèmes de la reconnaissance de la parole. [B11,B21]
Ce domaine de recherche concerne la reconnaissance, après une phase d'apprentissage, de quelques mots isolés pour un même locuteur. Elle se concrétisa en 1972 par l'industrialisation du VIP100, puis du VNC par la société Threshold Technology (30 mots reconnus avec un taux proche de 100%). [B1,B2,B10]
La fin de cette décennie fut marquée en France par Martine Kempf et son “Katalavox” [B3].
C'est une voie de recherche fondamentale qui concerne la reconnaissance et la compréhension de la parole continue, multilocuteur, à grand vocabulaire et langage peu contraint.
Cette méthode, basée sur l'identification d'éléments phonétiques, engendra ces années là un recours massif aux traitements du type intelligence artificielle pour pallier aux erreurs de décodage des phonèmes.
Trois systèmes issus du projet “ARPA/SUR ”virent le jour aux USA.
La recherche française aussi active produisit les systèmes “Myrtille 1 et 2” au C.R.I.N., Keal au C.N.E.T. de Lannion, Esope au L.I.M.S.I. à Orsay et Arial II au C.E.R.F.I.A. de Toulouse.
On remarque déjà, à la fin de ces années, l'importance prise par la modélisation “Markovienne du langage. [B1,B2,B10]
L'appareil phonatoire humain (Fig.2 et 3) peut être assimilé, et est même souvent modélisé comme un système composé d'une source et d'un filtre. La source est un élément qui vibre soit dans un mode harmonique, soit dans un mode “aléatoire” quand il y a une constriction au niveau des cordes vocales et donc un écoulement turbulent de l'air. Le filtre résulte du conduit vocal qui est formé d'une cavité résonante complexe. [B4,B5,B6]
Les cordes vocales sont les éléments vibreurs ; et comme une anche d'un instrument de musique, elles possèdent la particularité de produire, en plus de leur fréquence fondamentale, un spectre riche en harmoniques.
Mais un élément vibreur, placés devant une cavité résonante (Fig.1a), produira alors un son dont les fréquences seront filtrées par la bande passante du résonateur. (Fig.1b)
Les ordres de grandeur des fréquences fondamentales sont de 120Hz pour les hommes, 250Hz pour les femmes et de 450Hz pour les enfants. [B1,B10, B20]

Fig.1a [B4] Fig.1b [B4]
Le résonateur de l'appareil phonatoire est composé de quatre cavités principales en “série (Fig.2): le Pharynx ou arrière gorge (1), les deux cavités buccales (2 et 3) délimitées par la langue et que l'on simplifiera à une seule et l'ajutage labiale (4) situé entre les dents et les lèvres. La cavité nasale, en “parallèle” sur l'ensemble série précédent, vient compléter ce résonateur.
La source de ce résonateur est en fait décomposable en deux émissions distinctes et d'origines différentes. Les cordes vocales, en fournissant un spectre riche en harmoniques, produisent les sons voisés. Le bruit d'écoulement de l'air en provenance des poumons, dont le spectre est similaire à un bruit blanc, crée les sons non voisés.
Les sons et donc la parole naissent de l'excitation d'un résonateur et sont formés par les ouvertures et les volumes de ce dernier qui varient très rapidement.
L'observation spectrale du conduit vocal (Fig.4) laisse apparaître des pics de résonance, appelés formants. Les affaiblissements constatés dans le spectre, nommés anti-formants, sont introduits par les sons nasalisés.
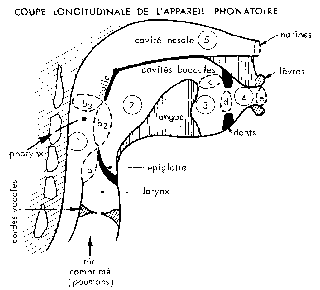
Fig.2 [B4]
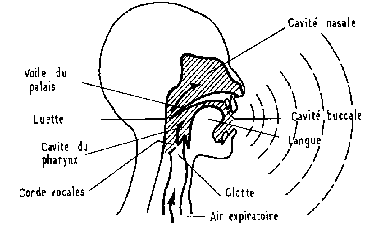
Fig.3 [B5]
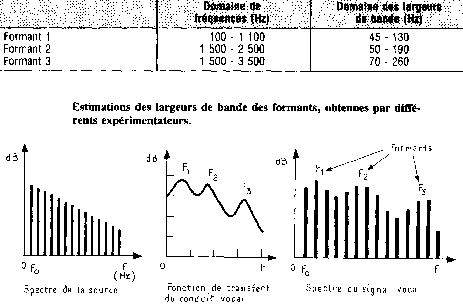
Fig.4 [B6]
Le signal de la parole véhicule plusieurs types d'informations, tels que le fondamental, la prosodie, le timbre et les phonèmes. Par conséquent, ceci impose, aux systèmes de reconnaissance vocale, de n'extraire que l'information nécessaire à son application, les phonèmes pour les machines de dictée par exemple.
La parole est surtout contenue dans les deux premiers formants, mais l'information proprement dite provient des transitions formantiques.
En général, on considère que la plage de fréquence d'un signal de parole se situe dans la bande de 100Hz-5KHz (300Hz-3.4KHz pour la téléphonie). [B7]
C'est
la plage des fréquences audibles comprises entre 20Hz et
20KHz, et entre le seuil d'audition, et le seuil de douleur (Fig.5).
Elle est caractérisée par la pression acoustique, dont
la référence à
![]() (Rappels :
(Rappels :
![]() et la pression atmosphérique standard égale 1013 hPa)
et le “phone”, référencé au 0dB
précédent mais pour 1KHz. [B4]
et la pression atmosphérique standard égale 1013 hPa)
et le “phone”, référencé au 0dB
précédent mais pour 1KHz. [B4]
On remarque sur la Fig.5 que l'intensité perçue est logarithmique par rapport à la puissance acoustique reçue et que cette intensité dépend elle même de la fréquence.
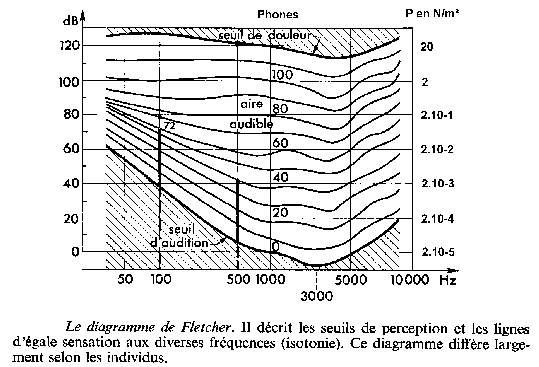
Fig.5 [B4]
Après 500Hz, l'oreille perçoit moins d'une octave pour un doublement de la fréquence. Des expériences psychoacoustiques ont alors permis d'établir la loi qui relie la fréquence et la hauteur perçue : l'échelle des Mels où le « Mel » est une unité représentative de la hauteur perçue d'un son (Fig.6). [B4,B7]
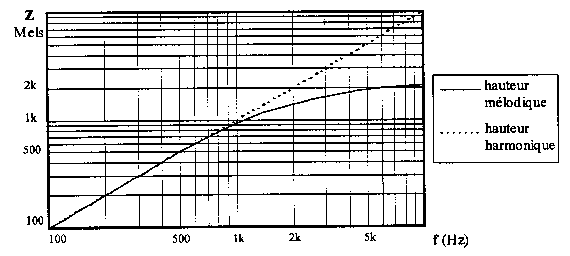
Fig.6 [B7]
Exemple : L'octave d'un son de 2000Hz (1800 Mels) sonnera l'octave supérieure à 4600Hz (3600 Mels) au lieu de 4000Hz.
Le système auditif se comporte comme un banc de filtres dont les bandes, appelées “bandes critiques”, se chevauchent et dont les fréquences centrales s'échelonnent continûment. Cette bande critique correspond à l'écartement en fréquence nécessaire pour que deux harmoniques soient discriminées dans un son complexe périodique. [B1,B7]
Remarque : Les échelles Mel ou de Bark sont approchées par un banc de 15 à 24 filtres triangulaires espacés linéairement jusqu'à 1KHz, puis espacés logarithmiquement jusqu'aux fréquences maximum. [B9,B14]
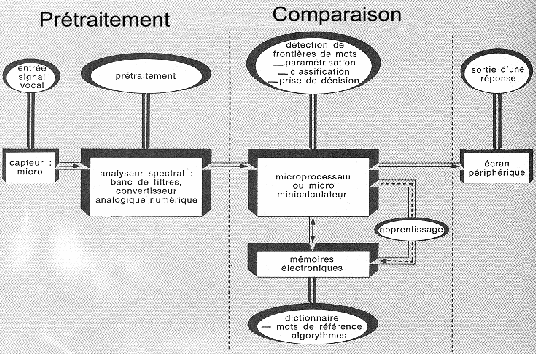
Le spectrographe de la parole est un appareil inventé voilà plus d'un demi siècle et commercialisé plus tard sous le nom de Sonagraph.
Historiquement, ce premier outil d'analyse pour les phonéticiens (Fig.7) était composé d'un banc de filtres analysant les différentes fréquences successivement.
Une autre technique de cet appareil est basée sur le filtrage hétérodyne : on fait défiler le signal vocal, modulé en amplitude par une sinusoïde variable en fréquence, sous un filtre fixe. On recueille alors l'énergie pour chaque incrément de fréquence. Le signal évoluant dans le temps, on obtient alors une représentation graphique à deux dimensions (fréquence temps), nommée “sonagramme (Fig.8) et dont l'intensité est représentée par une échelle de gris. [B1,B4]
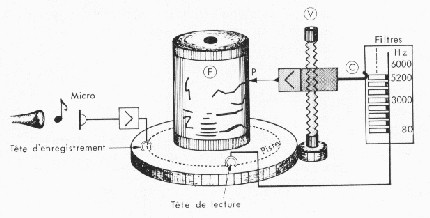
Fig.7 [B4]
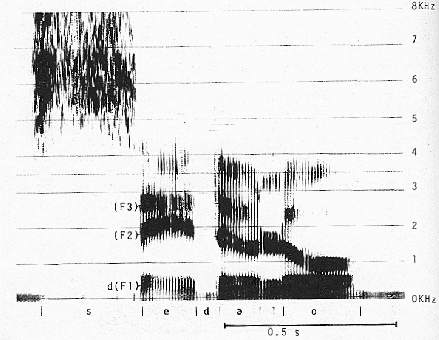
Exemple de sonagramme de la phrase : « c'est de l'eau »”.
Fig.8 [B1]
Les systèmes de reconnaissance vocale numériques (Fig.9) sont caractérisés par :
- le prétraitement qui comprend l'acquisition du signal de la parole et l'extraction des paramètres,
- l'apprentissage du vocabulaire et la comparaison aux références,
- le traitement des résultats en fonction de l'application finale.
Ces trois fonctions sont réalisées suivant deux approches : l'approche globale et l'approche analytique.
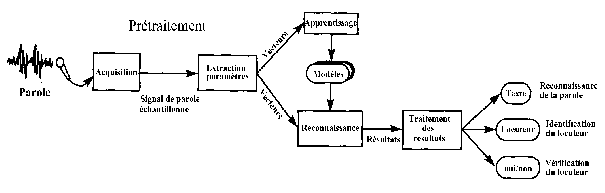
Fig.9 [B14]
Dans cette approche globale, dite aussi acoustique, on considère le message, mot ou groupe de mots, comme une forme insécable en lui attribuant une classe d'appartenance : le mot ou la phrase sont donc les unités de base du décodage et ne sont définis qu'à partir de paramètres purement acoustiques numérisés (Fig.10).
(Fig.10) [B2]
La reconnaissance globale comprend deux phases distinctes : [B1,B8,B10]
La phase d'apprentissage pendant laquelle un ou plusieurs locuteurs prononcent une ou plusieurs fois chacun des mots de l'application prévue. Ces prononciations sont toutes prétraitées puis conservées telles quelles ou bien moyennées dans un dictionnaire de références en tant que “ images acoustiques ”.
Puis la phase de reconnaissance où le signal à reconnaître subit le même prétraitement que la phase précédente. Il est ensuite comparé aux références contenues dans le dictionnaire. Le calcul d'une « distance » et sa comparaison à un seuil permet ou non de retenir la ou les références les plus proches.
Mais les différences de prononciations et les variations de débit d'élocution, parfois importantes et non linéaires imposent l'utilisation d'algorithmes de comparaison tels que la comparaison dynamique ou les chaînes de Markov. [B1,B7,B8,B10]
C'est une méthode bien adaptée aux applications monolocuteur, à faible vocabulaire et plutôt à mots isolés.
Par cette approche, appelée aussi analyse phonétique, on considère la segmentation du message en constituants élémentaires tels que les phonèmes, les diphonèmes ou les triphonèmes (Fig.11). En effet, ces éléments présentent l'avantage d'être en nombre réduit : 37 phonèmes permettent de décrire le français parlé et une analyse statistique réalisée au LIMSI a montré, qu'à partir d'un répertoire de 627 diphonèmes, il était possible de reconstituer n'importe quelle phrase en français. [B21]
Quant au triphonème, ou triplet phonétique, il est constitué d'un phonème et de ses transitions antérieures et postérieures. Ils sont bien sûr en plus grand nombre, mais ils ont l'avantage de prendre en compte la coarticulation des phonèmes.
Le caractère continu du signal vocal complique beaucoup la reconnaissance de la parole : aucun indice acoustique ne permet de localiser les frontières de mots. Ce problème est abordé, après la phase de prétraitement, d'une part par un décodage acoustique-phonétique (DAP) permettant la transcription de la phrase sous forme d'une suite d'éléments phonétique du langage ; et d'autre part par un traitement linguistique faisant appel à diverses sources d'informations (lexicales, syntaxiques, sémantiques) permettant la reconnaissance des mots. [B11]
Ce sont donc des systèmes à architectures logicielles complexes à plusieurs sources de connaissances qui pallient aux problèmes de reconnaissances des phrases. [B1,B10]
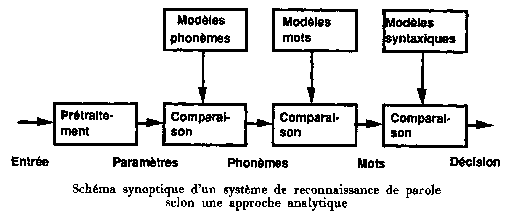
Fig.11 [B10]
La parole est un phénomène non stationnaire, c'est à dire, ses propriétés statistiques changent continuellement dans le temps. Cependant, l'observation du signal de la parole indique qu'il n'évolue pas ou peu sur des durées de quelques millièmes de secondes. On peut donc considérer ce signal comme étant stationnaire durant ce temps (stationnarité locale). [B1,B9,B11]
Le signal issu du microphone est d'abord amplifié, filtré par un filtre anti-repliement et échantillonné par blocs de 16 à 32ms à des fréquences variant de 8KHz à 16KHz. [B11]
Un recouvrement à moitié des fenêtres d'acquisition améliorées, de type Hamming (Fig.12&13), permet de raccorder les fenêtres en minimisant les “« trous »” et les « bosses »”. [B14]
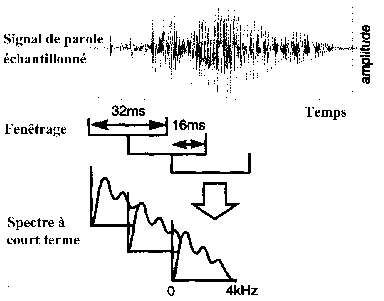
Fig.12 [B14]
L'information portée par le signal de la parole est essentiellement contenue dans les formants. Il est donc nécessaire d'affranchir ces derniers de signaux indésirables tels que la source ou le « bruit »” de numérisation (enveloppe spectrale en dent de scie).
Les systèmes de prétraitement permettent donc d'améliorer la représentation des formants par « lissage »”, et de fournir, à l'outil de comparaison, des vecteurs constitués de coefficients pertinents.
Les méthodes les plus courantes pour le traitement du signal de la parole sont les analyses spectrales réalisées soit par transformée de Fourier à court terme, soit par prédiction linéaire ou soit par évaluation des coefficients cepstraux. [B15]. D'autres méthodes existent, telles que la représentation par formes d'ondes et la représentation en ondelettes de Morlet. [B7]
Le signal de la parole, échantillonné et préaccentué dans les hautes fréquences, est prélevé par une fenêtre temporelle glissante de type Hamming (Fig.13).
Puisque c'est la largeur de cette dernière qui détermine la résolution spectrale de l'analyse, il apparaît donc un conflit entre la résolution temporelle et la résolution fréquentielle, comme l'indique l'exemple suivant :
pour
une fe = 12 kHz et N=256 ®
![]() et w(t)=N.Te=21ms,
et w(t)=N.Te=21ms,
N=40 ®
![]() et w(t)=3.3ms.
et w(t)=3.3ms.
On peut conclure qu'une analyse en bande étroite, d'une résolution fréquentielle de 50Hz environ, permet une bonne représentation de la structure harmonique du signal. Mais cette dernière se fait au détriment de la résolution temporelle qui se traduit par une intégration des évolutions temporelles rapides.
Une transformée de Fourier est ensuite calculée pour chaque valeur de décalage de la fenêtre. [B7].
TFCT
(temps continu) :
![]() [B7]
[B7]
TFCT
(temps discret) :
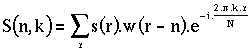 [B7]
[B7]
avec
![]() et N le nombre de points prélevés.
et N le nombre de points prélevés.
En prenant le carré du module de la TFCT, on obtient alors un spectrogramme représentant la distribution énergétique dans le plan temps fréquence, puisque pour chaque instant « n », on dispose alors de l'énergie associée aux fréquences k=0, ..., N-1.
Il suffit alors d'appliquer un filtrage suivant une échelle de Mel ou de Bark, fréquemment utilisée en reconnaissance vocale, pour obtenir un superbe sonagraphe numérique ! [B7,B11]
En conclusion, la TFCT présente l'avantage de vecteurs de paramétrisation constitués d'une vingtaine de composantes obtenus avec un faible volume de calcul donnant une image proche de celle du sonagraphe.
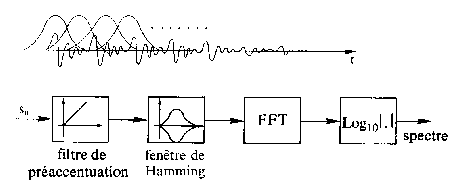
Fig.13 [B1]
La prédiction linéaire est une technique qui s'applique directement après l'échantillonnage et la quantification du signal de la parole. C'est une méthode permettant l'approximation du signal par un modèle. Pour cela, elle considère l'appareil phonatoire comme un modèle source-filtre linéaire. [B7]
Par conséquent, un échantillon de parole peut-être prédit par une combinaison linéaire d'un certain nombre d'échantillons précédents : [B6,B13]
![]()
Où s(n) représente le signal à l'instant « n »”
e(n) représente un bruit blanc dû à toutes les sources d'erreurs possibles (précision des termes, arrondis de calcul, ...).
Estimation
du signal à l'instant « n » :
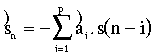 [B13,B20]
[B13,B20]
avec p l'ordre de prédiction.
L'erreur
de prédiction est égale à
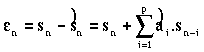 [B13,B20]
[B13,B20]
Les coefficients de prédiction sont calculés, afin de minimiser cette erreur, par plusieurs méthodes : moindres carrés,...
La
transformée en z de
![]() donne :
donne :
![]()
![]()
Si
on se fixe e(z)
par une constante e,
on a alors
![]() [B13]
[B13]
En
posant
![]() et
et
![]() avec
avec
![]() ,
,
on peut alors représenter la densité spectrale de puissance (DSP) de S(z) :
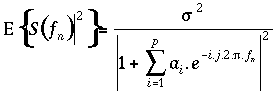
où
![]() :
puissance de l'erreur.
:
puissance de l'erreur.
La détermination de la densité spectrale de puissance revient donc à calculer les coefficients de prédiction ai.
Conclusion : L'analyse par prédiction linéaire permet de passer d'un spectre échantillonné, donc « bruité »” à une représentation spectrale continue et « lissée ».
La détection des formants en est alors plus aisée (Fig.14).
Cette méthode présente l'inconvénient du choix du nombre de coefficients (8 à 14) à prendre en fonction de la fidélité par rapport au signal analysé. [B1]
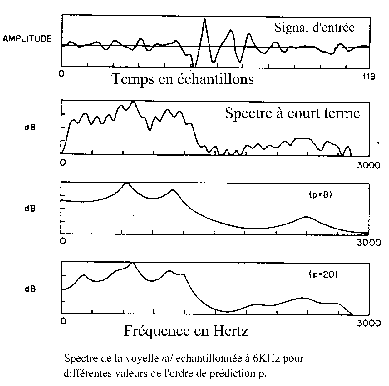
Fig.14
Comme nous l'avons vu précédemment, le signal de la parole est porteur de différentes informations, dont le fondamental, qui ne sont pas toutes nécessaires à la compréhension du message. Ce signal est le résultat d'une multiplication du spectre d'entrée par la réponse fréquentielle du conduit vocal. Dans ce cas, tout le contenu spectral du signal source, modifié par le conduit vocal, ne peut pas être éliminé par filtrage, puisque précisément cette opération de filtrage est adaptée à l'extraction d'information localisée en fréquence. Une alternative consiste à utiliser la méthode « cepstrale ». En effet, celle-ci est basée sur l'opérateur logarithme qui transforme un produit en addition, ce qui permet alors de séparer la source du conduit vocal.
Le cepstre est défini comme la Transformée de Fourier inverse du module d'un spectre exprimé en échelle logarithmique. [B7]
![]() [B7]
[B7]
où : « c »” indique le domaine cepstral, appelé aussi domaine « pseudo-temporel »”,
« k » la variable cepstrale exprimée en « quéfrence »” et homogène à un temps.
Après la séparation du conduit vocal et de la source (Fig.15a), on procède à une opération de « liftrage » (Fig.15b) pour éliminer toutes les quéfrences dépassant un certain seuil (voir seuils de quéfrences a, b et c sur la Fig.16). Le retour au domaine fréquentiel s'effectue par une FFT dont on calcule ensuite l'exponentielle (Fig.15c). On obtient alors un spectre lissé constitué de l'information formantique (Fig.16). [B21]
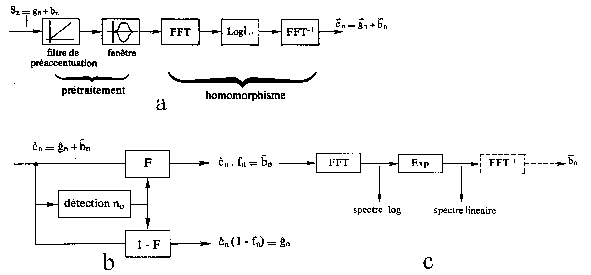
Fig.15 [B1]
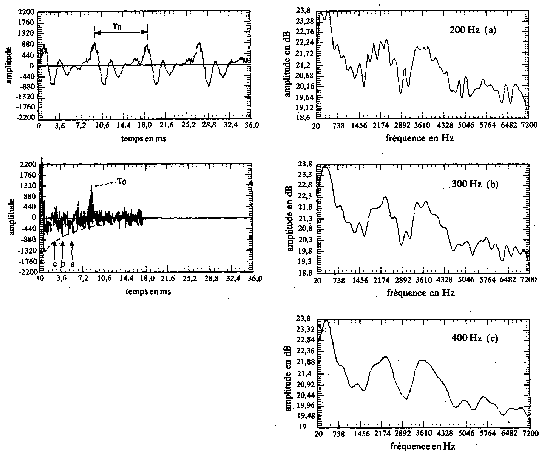
Fig.16 [B1]
L'analyse MFCC consiste en l'évaluation de Coefficients « Cepstraux » à partir d'une répartition Fréquentielle selon l'échelle des Mels [B1]. Mais il faut noter, dans l'analyse MFCC décrite ci-dessous, que les coefficients cepstraux obtenus ne correspondent pas exactement à la définition du cepstre défini précédemment. [B1,B14]
Cette technique est composée dans un premier temps d'une analyse spectrale (§3521) ou d'une analyse LPC (§3522). L'étendue dynamique du spectre de puissance ainsi obtenu permet sa compression logarithmique afin de s'accorder avec la perception d'intensité de l'oreille humaine.
Pour finir, une transformée discrète en cosinus (DCT) est appliquée afin d'obtenir les Nc coefficients cepstraux.
![]() [B7]
[B7]
avec
![]() et f(i) la i-ième des Nf sorties log du banc de filtres.
et f(i) la i-ième des Nf sorties log du banc de filtres.
Ces derniers, ajoutés à des coefficients représentant l'information énergétique et de dérivées première et seconde, forment alors un vecteur acoustique. (Fig.17). [B9,B14]
Les avantages de cette méthode sont les suivants :
- Le nombre de données par vecteur est réduit. En pratique, pour 24 filtres (Nf=24), il a été montré que 12 coefficients cepstraux (Nc=12) suffisent pour représenter l'information, puisque l'enveloppe de la DSP varie lentement.
- Les valeurs des vecteurs sont relativement décorellées entre elles, ce qui est idéal pour la reconnaissance de forme. [B14]
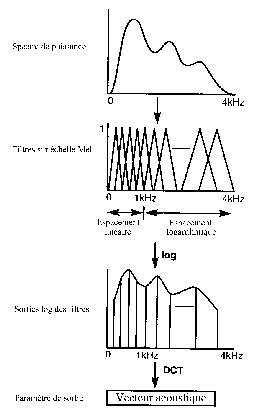
Fig.17 [B14]
La représentation par formes d'ondes consiste à développer le signal sur une base d'ondes sinusoïdales à enveloppes gaussiennes (GSM). Cette méthode décrite en [B22] ne sera pas étudiée ici car elle se rapproche de la représentation en ondelettes développée ci-après [B7].
Cette méthode peut être interprétée comme une « analyse de Fourier locale ».
En effet, la particularité des ondelettes est de posséder un nombre constant de périodes. Autrement dit, la durée de leur support temporel varie selon la fréquence d'analyse. Par conséquent, elle permet d'observer un phénomène basse fréquence sur une longue durée et réciproquement, d'observer un phénomène haute fréquence sur une courte durée. [B7]
L'ondelette mère de Morlet (tronquée), représentée fig.18, est définie ainsi :
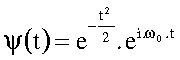 [B7]
[B7]
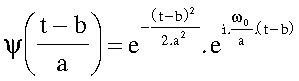 [B7]
[B7]
Le facteur « b » représente la translation temporelle de l'ondelette d'analyse par rapport au signal de la parole.
L'accroissement du paramètre d'échelle « a » entraîne, d'une part, un déplacement de la bande analysée vers les basses fréquences, et d'autre part, le rétrécissement de cette bande fréquentielle due à l'élargissement de la fenêtre temporelle Gaussienne.
On
peut donc assimiler cette analyse à un filtre à
translation fréquentielle et à coefficient de qualité
![]() constant.
constant.
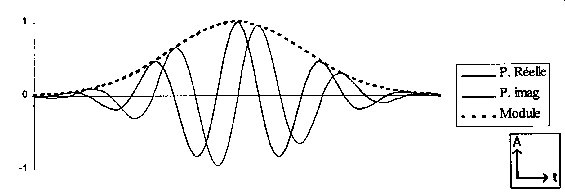
Fig.18 [B7]
En conclusion et en comparaison avec la TFCT, la transformée en ondelettes permet de mieux représenter les évolutions spectrales rapides, puisque sa résolution fréquentielle est relative à la fréquence explorée, alors que la TFCT se comporte comme un banc de filtres à résolution fréquentielle Df constante.
Cette méthode permet, grâce à sa meilleur résolution, de bien suivre les évolutions du signal de la parole.
Lorsqu'un locuteur prononce deux fois un même mot, les spectrogrammes, vecteurs précédemment obtenus, ne seront jamais exactement les mêmes. Il y aura des différences non linéaires dans le temps (rythme) qui nécessitent « d'aligner les axes temporels ». [B8]
Soit « i », i Î [1, I], un vecteur issu de la paramétrisation et appartenant au mot test,
Soit « j », j Î [1, J], un vecteur appartenant au mot du dictionnaire de référence,
et d(i,j) la « distance » euclidienne :
Si
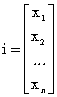 et
et
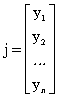 alors
alors
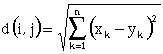
å La distance d(i,j) représente la distance entre le spectre de la référence et le spectre du test aux instants i et j. [B8]
å g(i,j) représente la distance cumulée et est calculée en respectant les propriétés de monotonie et d'évolution lente du signal étudié. C'est à dire, les seuls chemins valides arrivant au point (i,j) viennent des points (i-1,j), (i-1,j-1) ou (i,j-1).[B1]
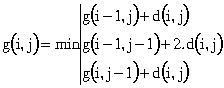 [B8]
[B8]
å G est la distance normalisée entre les deux prononciations du mot et est défini par :
![]() [B8]
[B8]
La méthode de la comparaison dynamique consiste à choisir, parmi tous les chemins physiquement possibles, la référence pour laquelle la distance totale “ G ” est la plus faible et qui représente le chemin le plus court. L'étiquette du mot reconnu peut alors être fournie comme un résultat.
Si la distance est trop élevée, en fonction d'un seuil pré-défini, la décision de non reconnaissance du mot est alors prise ; cela permet de rejeter les mots qui n'appartiennent pas au dictionnaire de référence.
La ressemblance idéale se traduit donc par une diagonale (Fig.19). [B1,B7,B8]
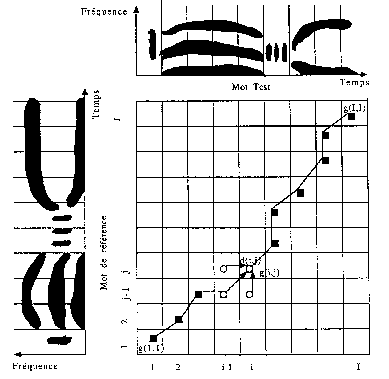
Fig.19 [B8]
Une chaîne de Markov est constituée d'états et d'arcs entre ces états. Les arcs, à qui on associe une probabilité de transmission, permettent de passer d'un état au suivant, de sauter un état, ou au contraire de rester sur un état. Dans une chaîne de Markov, on connaît, à tous les instants de la progression, les états et leurs probabilités de transitions.
Alors que dans un modèle de Markov cachée (HMM), les états ne sont pas connus. C'est donc des observations extérieures, tels que les vecteurs issus du prétraitement, qui, associés aux probabilités de transition, permettront la progression dans la chaîne. Il suffit ensuite, grâce à l'algorithme de Viterbi par exemple, de retrouver les chemins (états) parcourus et de conserver la liste des états visités la plus probable. [B17]
Un modèle de Markov est donc représenté par un triplet (S, Tr, Ob) avec : [B7]
å S, l’ensemble des états correspondant aux unités élémentaires du langage, telles que les phonèmes.
å Tr, la matrice des probabilités de transitions entre phonèmes, liée au vocabulaire de la langue,
å Ob, la matrice des émissions formée des probabilités d'observation de vecteurs images en fonction de chaque état (phonème) du système.
Un exemple, réduit à trois phonèmes possibles et six observations caractéristiques différentes, permet de mieux appréhender cette méthode (Fig.20).
On connaît, d'après le dictionnaire de cette langue à trois phonèmes, les probabilités de succession de ces derniers et que l'on représente par un diagramme (fig.20) ou par une matrice des transitions Tr(i,j) : [B7, B17]
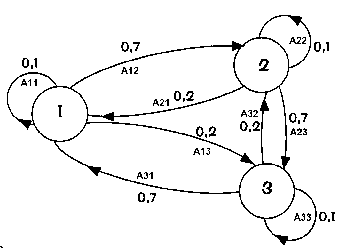
Fig.20
Matrice
des transitions :
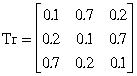
Soit les observations A, B, C, D, E et F caractérisées par les coefficients du prétraitement (24 pour une TFCT sur échelle de Bark par exemple).
Par expérience, on sait que le phonème Ph1 est très souvent le résultat de l'observation D, mais il arrive qu'il soit aussi issu d'autres observations. Il faut donc quantifier chaque phonème émis par des probabilités d'observations : [B17]
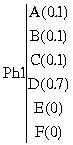
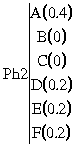
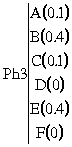
Matrice
des émissions :

Au
début de l'élocution, on ne peut pas connaître le
premier état (phonème), on affecte donc au vecteur de
démarrage des probabilités égales :
![]() ,
soit trois états équiprobables.
,
soit trois états équiprobables.
L'algorithme de Viterbi consiste à ne conserver que la probabilité de transition maximale et par conséquent, l'état visité.
Le processus consiste à recevoir, de la cellule de prétraitement, une suite d'observations servant de base à l'algorithme pour retrouver la suite la plus probable de phonèmes :
![]()
![]()
Interprétation des deux premiers états :
C'est la phase d'initialisation : J'observe « D » donc seuls Ph1 et Ph2 sont possibles. Sachant que les états de départ sont équiprobables, il faut calculer les probabilités des six combinaisons possibles :

On constate de suite que la troisième ligne est la plus probable et que l'état stable est le phonème Ph1.
L'observation suivante, « A », correspond à trois choix possibles :
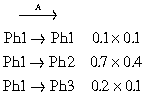
Les calculs effectués nous informent que c'est l'état Ph2 qui succède à l'état Ph1.
Il suffit donc de parcourir toute la chaîne des observations par cette méthode pour retrouver les phonèmes correspondant aux observations.
Cette technique est considérée comme sans mémoire car elle ne tient compte que de l'état actuel sans se préoccuper de ou des états précédents (de l'état actuel, les possibilités sont... tout en observant que...).
L'avantage de cette méthode réside dans sa capacité à reconnaître des unités élémentaires de la parole en s'appuyant sur les règles connues du langage et sur la suite des observations effectuées sur le signal. On peut conclure que cette méthode, grâce à sa phase d'apprentissage qui permet d'affiner ses « connaissances », s'adapte particulièrement bien à la reconnaissance multilocuteur à grands vocabulaires. [B7,B10]
Un examen de l'évolution temporelle d'un signal représentant la parole montre que les phonèmes successifs ne sont pas simplement juxtaposés : il apparaît des phases transitoires difficiles à localiser exactement ; on ne sait pas, par exemple, quand un phonème commence et quand il finit.
Le processus de décodage acoustique phonétique, connu sous le nom de DAP, consiste
à découper le signal de la parole en segments (phase de segmentation), puis à identifier ces segments et à leurs affecter une étiquette phonétique (phase d'identification). [B11]
La segmentation en unité élémentaire, syllabe, demi-syllabe, phonème, diphonème ou triphonème, s'appuie sur la recherche des discontinuités du signal ou de son spectre au cours du temps. [B8]
L'identification consiste alors à comparer chaque spectres de ces segments à un ensemble de spectres de référence et à conserver les plus ressemblants. Les techniques de comparaison couramment employées s'appuient sur des méthodes classiques, décrites précédemment, qui tiennent compte des variations individuelles (accents, coarticulation, liaisons) et prosodiques (rythme, intensité, mélodie). [B1,B8]
Le décodage acoustique phonétique sert donc de base en fournissant une chaîne phonémique aux traitements linguistiques qui viennent ensuite (Fig.21).
Cette méthode possède l'avantage indéniable d'un volume de calcul réduit.
En effet, il ne dépend que du faible nombre d'éléments à étiqueter, 37 si l'unité est le phonème, contrairement aux très nombreux mots possibles du dictionnaire.
Les traitements linguistiques sont destinés à fournir un sens au message émis par le locuteur, il faut donc le décoder à différents niveaux en faisant appel à un ensemble de sources d'informations de natures très diverses : (Fig.21)
- L'analyse lexicale fournit les mots possibles à partir du DAP.
- L'analyse syntaxique regroupe l'ensemble des informations liées à la structure des phrases en fonction des règles grammaticales du langage.
- L'analyse sémantique est liée à la signification des mots et aux concepts (idées) sous-jacents.
- L'analyse pragmatique, indispensable pour la compréhension, recouvre l'ensemble des informations relatives au contexte de l'application et à l'historique du dialogue. [B11]
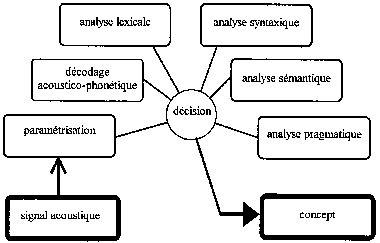
Fig.21 [B7]
La coopération au mieux de ces diverses sources d'informations repose sur des méthodes d'intelligence artificielle dont la plus couramment utilisée porte le nom de « best-first » (meilleur d'abord). Cette dernière consiste à retenir, à tout moment, le constituant (phonème, mot) le plus plausible, jusqu'à ce que l'on atteigne la fin de la phrase. Une impossibilité impose le retour en arrière et augmente, par conséquent, les temps de calcul.
Les applications très diverses de la reconnaissance vocale peuvent être regroupées suivants trois grandes familles de systèmes : [B15]
Cette catégorie regroupe les systèmes à petit vocabulaire, dont le mode d'élocution est isolé ou continu , résistant au bruit, dépendant ou indépendant du locuteur.
C'est la signification du message, prononcé en parole continue à vocabulaire restreint, qui caractérise cette famille.
Ces systèmes sont capables de transcrire un texte dicté par un locuteur.
On a donc à faire à un flux de parole continu où la compréhension n'est pas demandée mais qui requiert une analyse syntaxique et contextuelle des phrases.
C'est un classement en trois catégories où l'on s'intéresse plutôt à la nature de l'information disponible en sortie des systèmes de reconnaissance vocale. [B14]
Ce domaine est relativement simple car les mots prononcés sont séparés par des silences de durées supérieures à quelques dixièmes de secondes (200ms).
La technique de reconnaissance globale s'applique facilement car les images acoustiques des mots peuvent être facilement isolées. [B1]
Cette méthode diffère de la précédente dans la phase d'apprentissage qui est subdivisée en deux autres phases : l'apprentissage en mode « mots isolés » et l'apprentissage en séquences de deux à trois mots. Le système analyse ces séquences et en extrait les références. En conséquence, la mémoire des références contient plusieurs exemplaires de chaque mots. Cette technique, comparée à la précédente, possède, en plus, la difficulté de la segmentation de la séquence en mots, liée aux problèmes de la coarticulation. [B1]
Connue sous le nom de « word spotting », cette technique s'applique surtout aux systèmes de commande vocale. Elle nécessite au moins deux syllabes pour la reconnaissance des mots clés, sinon ces derniers seraient souvent détectés à l'intérieur de mots plus longs. Elle est particulièrement adaptée au filtrage des informations superflues telles que « Ah, oh oui merci... ». [B14]
La reconnaissance du locuteur est l'aspect dual de la reconnaissance de la parole. C'est à dire, on essaie de trouver ce qui, dans un signal vocal, est caractéristique de l'individu qui a parlé, alors qu'au contraire, les systèmes de reconnaissance de parole multilocuteur cherchent à s'affranchir de ces variations.
Les systèmes à approche globale se prêtent bien à ce type d’application, ils sont néanmoins différenciés des systèmes précédents dès l’analyse acoustique (Fig.22).
En effet, on ne cherche plus à s'affranchir du fondamental, mais au contraire, à l'analyser pour en tirer les paramètres additionnels représentatifs des traits du locuteur et nécessaires à la reconnaissance de sa voix..
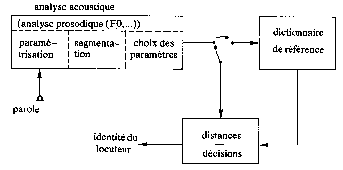
Fig.22 [B1]
L'identification est un domaine où il convient de comparer un message vocal avec un ensemble de références acoustiques correspondant à plusieurs personnes. Cet examen vocal permet de déterminer la personne qui a parlé, la variable de sortie d'un tel système est donc un nom. Néanmoins, les caractéristiques d'un locuteur évoluent fortement avec le temps et dépendent de nombreux facteurs. Pour ces raisons, il convient d'être prudent en matière de fiabilité (justice). [B16]
Ce système diffère du précédent puisque le locuteur décline préalablement son identité. Il s'agit donc de vérifier si son identité correspond à celle qu'il prétend avoir.
Cette technique, qui touche bien sûr les secteurs à accès contrôlés, peut être complétée d'une dépendance au texte prononcé, telle qu'un mot de passe.
La variable de sortie est alors binaire, oui ou non, accès permis ou accès refusé.
En remarque, il convient de préciser que la vérification et l'identification du locuteur peuvent bien sûr être complémentaires. [B1]
La différenciation entre produits, telle que la reconnaissance vocale, est un argument important pour la vente. La particularité technique de cet atout commercial impose aux fabricants l'utilisation d'outils ou d'interfaces de développement (Tableau 2) leur permettant d'intégrer un module de reconnaissance dans leurs applications.
|
Société |
Référence Produit |
Type |
Support |
Approche Comparaison |
Reconnaissance |
Application |
Nombre de mots |
Prix (F) |
|
Oki |
MSM6679 |
C.I. |
carte |
|
multilocuteur monolocuteur |
commande vocale |
25 61 |
120
|
|
Oki |
MSM6679A |
C.I. |
carte |
|
multilocuteur |
commande vocale |
40 |
85 |
|
Ricoh |
RL5S840 |
C.I. |
carte RVZ2000 |
|
multilocuteur |
|
60 |
60 |
|
Sensory |
RSC-64 |
C.I. |
carte RSC |
|
monolocuteur multilocuteur |
|
14 60 |
30 |
|
Sensory |
Voice Password |
C.I. |
carte |
|
monolocuteur |
mot de passe |
16 |
36 |
|
AT&T |
WASAP |
logiciel |
Windows |
|
multilocuteur |
interface téléphonie |
1000 |
2400 |
|
Dialogic |
Antares DSP |
logiciel+carte |
cart.Spox à 4 DSP Texas |
|
multilocuteur |
téléphonie dictée |
dépend du logiciel |
21000 |
|
Dragon |
Speech tool |
logiciel |
Windows |
globale |
multilocuteur |
dév. divers |
faible |
1800 |
|
Dragon |
Dragon XTools |
logiciel |
Windows |
analytique |
multilocuteur |
dictée |
60000 |
1800 |
|
Entropic C.R.L. |
outil HTK |
logiciel |
Unix |
analytique HMM |
monolocuteur multilocuteur |
dév. Divers |
limité mémoire |
42000 |
|
IBM |
Voicetype Toolkit |
logiciel |
Windows |
globale |
multilocuteur |
commande vocale |
faible |
libre Web |
|
Learnout&Hauspie |
ASR1500 /M ASR |
logiciel |
Windows |
|
multilocuteur |
dév.divers |
limité mémoire |
4800 |
|
Learnout&Hauspie |
ASR1500/T |
logiciel |
Unix |
|
multilocuteur |
téléphonie |
limité mémoire |
4800 |
|
Nuance Commu-nication |
Nuance Toolkit |
logiciel |
Unix +carte |
|
multilocuteur |
téléphonie |
160000 |
30000 |
|
Philips |
Speech Magic |
logiciel+DSP |
Windows + carte |
|
monolocuteur multilocuteur |
dictée |
64000 |
21000 |
|
Pure speech |
Recite Soft dev.kit |
logiciel+carte |
Unix Windows |
|
multilocuteur |
téléphonie |
2000 |
45000 |
|
Speech Solutions |
Voice tools |
logiciel |
Windows |
|
multilocuteur |
dictée |
30000 |
1800 |
|
BBN Hark SC |
Hark recogniser |
logiciel |
Windows Unix |
Analytique HMM |
multilocuteur |
commande entrée données mot de passe |
100000 2000actif |
2400 |
|
ALTech |
Speech-Works |
logiciel |
Windows Unix |
Analytique |
multilocuteur continu |
téléphonie divers |
100000 |
|
|
Speech Systems |
VoiceMatch |
logiciel |
Windows |
|
multilocuteur |
|
2000 |
6000 |
Tableau 2 : Outils de développement ASR [B18,B19]
|
Société |
Référence Produit |
Type |
Support |
Approche Comparaison |
Reconnaissance |
Application fonction |
Nombre de mots |
Prix (F) |
|
dragon Systems |
Dragon Dictate |
logiciel |
Windows |
Analytique HMM |
monolocuteur continue |
commande dictée |
5000 à 60000 |
2400 10200 |
|
Fonix Siemens |
|
DSP |
|
Analytique Rés. neurones |
multilocuteur
|
téléphonie |
|
|
|
IBM |
VoiceType 3.0 |
logiciel |
Windows |
Analytique HMM |
multilocuteur mots isolés |
dictée |
35000 à 65000 |
|
|
IBM |
VIAVOICE Gold |
logiciel |
Windows |
Analytique HMM |
multilocuteur continu |
dictée commande |
65000 à 350000 |
1235 |
|
DeDris Xilinx |
|
DSP |
|
Globale |
monolocuteur mots isolés |
|
|
|
|
Spectro-chip |
Voice Security C. |
carte |
P.C. |
|
identification vérification |
protection informatique |
|
|
|
Nuance Communications |
Nuance Verifier |
logiciel |
Pentium 100MHz |
Globale |
vérification locuteur permanente |
Sécurité transaction téléphone |
temps réel |
|
|
VOX |
|
4 DSP TMS320C31 |
carte |
Analytique MFCC HMM |
mots isolés
|
France Télécom Gd Public |
|
|
|
Nuance Communication |
Nuance 6 |
logiciel |
Unix IVR platforms |
Analytique HMM |
|
téléphonie commande dictéee |
15000 |
|
|
Ariel |
RA 201/PC |
DSP |
carte |
|
mots isolés |
|
|
|
|
Kurzweil A.Intell. |
Kurzweil voice 1.5 |
logiciel |
windows |
Globale
HMM |
monolocuteur discontinue continue nombre |
commande dictée |
30000 à 60000 |
6000 |
Tableau 3 : produits finis
Au terme de ce bilan rapide sur la reconnaissance vocale, on a pu constater que ce domaine est particulièrement vaste et qu'il n'existe pas de produit miracle capable de répondre à toutes les applications. Le bruit, par exemple, non traité par ce document, reste un frein à la généralisation des systèmes de reconnaissance. [B16]
La reconnaissance vocale reste un compromis entre la taille du vocabulaire, ses possibilités multilocuteur, son encombrement physique, sa rapidité, temps d'apprentissage, etc...
La puissance des outils de calcul actuels et les capacités d'intégration des systèmes ont provoqué un regain d'intérêt depuis ces dernières années chez les industriels. En effet, ces derniers voient dans la reconnaissance vocale, « le plus commercial »”, permettant de faire la différence avec la concurrence.
Un rapide tour d'horizon sur les très nombreuses publications permet de se fixer les idées sur la nature des travaux en cours. Hormis les produits dédiés à la reconnaissance de la voix, les systèmes à approche analytique (HMM) donnent aujourd'hui les meilleurs résultats et ont actuellement le vent en poupe.
Quant aux perspectives d'avenir, l'optimisme est plus mesuré que dans le passé. Sans risque, on peut affirmer que le problème général du traitement automatique de la parole ne sera sans doute pas réglé avant le milieu du siècle prochain [B10].
SIGLES et ABREVIATIONS
|
ARPA/SUR |
Advanced Research Projects Agency/Speech Understanding Research. |
|
ASR |
Automatic Speech Recognition. |
|
C.E.R.F.I.A. |
Cybernétique des Entreprises, Reconnaissance des Formes et Intelligence Artificielle. |
|
C.N.E.T. |
Centre National d'Etudes des Télécommunications. |
|
C.R.I.N. |
Centre de Recherche en Informatique de Nancy. |
|
DAP |
Décodage acoustique phonétique. |
|
DCT |
Discret Cosinus Transform, Transformée en Cosinus Discrète. |
|
DSP |
Déf.1: Processeur digital de signaux |
|
DTW |
Dynamic Time Warping, Alignement Temporel Dynamique |
|
GSM |
Gaussian Sine Modulated, Modulation Sinusoïdale à enveloppe Gaussienne |
|
L.I.M.S.I. |
Laboratoire d’informatique pour la Mécanique et les Sciences de l’Ingénieur. |
|
LPC |
Linear predictive coding, codage à prédiction linéaire. |
|
L.V.R. |
Large Vocabulary continuous speech Recognition, reconnaissance de la parole continue à grand vocabulaire. |
|
MFCC |
Mel Frequency Cepstral Coefficients. |
|
TFCT |
Transformée de Fourier à Court Terme |
|
TSR |
Telephone-based Speech Recognition |
GLOSSAIRE
|
Ajutage |
Orifice percé dans la paroi d'un réservoir. |
|
Anche |
Languette dont les vibrations produisent les sons dans certains instruments à vent. |
|
Coarticulation |
Variabilité de la réalisation d'un phonème en fonction de ses conditions de production (contexte phonique, facteurs individuels, vitesse,...). |
|
Continuous speech |
Langage en parole continue utilisant les « mots enchaînés ». |
|
Discrete speech |
Langage utilisant la technique des « mots isolés ». |
|
Euclidien |
Espace vectoriel euclidien, espace vectoriel muni d'un produit scalaire. |
|
Hétérodyne |
Qui effectue un changement de fréquence. |
|
Homomorphisme |
Représentations différentes contenant la même information. Application mathématique : F ® G tel que f(x).f(y) = g(x)+g(y). |
|
Markovien (ne) |
Markov (Andreï Andreïevitch), mathématicien russe (Riazan 1856 - Petrograd 1922). En théorie des probabilités, il introduisit les chaînes d'événements dites “ chaînes de Markov ”. |
|
Monolocuteur |
(Speaker dependant). Système nécessitant un apprentissage de la voix du locuteur. |
|
Mots enchaînés |
(Connected word). Mots non séparés par des pauses. |
|
Mots isolés |
(Isolated word). Mots séparés par des pauses. |
|
Multilocuteur |
(Speaker independant). Système fonctionnant avec tout locuteur. |
|
Phone |
Unité servant à comparer la puissance des sons de fréquences différentes du point de vue de l'impression ressentie. |
|
Phonème |
Elément sonore d'une langue se définissant par ses propriétés distinctives. |
|
Phonétographe |
Appareil traduisant l'onde sonore en élément phonétique. |
|
Pragmatique |
Fondé sur les faits, le contexte. |
|
Prosodie |
Partie de la phonétique qui étudie l'intonation, l'accentuation, les tons, le rythme, les pauses, la durée des phonèmes. |
|
Sémantique |
Qui se rapporte à l'interprétation, à la signification d'un système (par opp. à syntaxique). |
|
Sonie |
Intensité de la sensation sonore, en relation avec la pression acoustique. Unité : le sone. |
|
Stochastique |
Qui est de nature aléatoire. Processus stochastique. |
|
Syntaxique |
Qui se rapporte à l'aspect formel d'un langage, (par opp. à sémantique). |
|
Timbre |
Qualité particulière du son, liée aux intensités relatives des harmoniques qui le composent. |
|
Word spotting |
Technique de reconnaissance où le système repère les mots utiles dans une phrase prononcée en langage naturel |
BIBLIOGRAPHIE
|
[B1] |
La parole et son traitement automatique. Par Calliope (nom collectif représentant les 36 auteurs de cet ouvrage). Editions Masson, 1989. |
|
[B2] |
L'usine Nouvelle N°22, « L'ordinateur à l'écoute depuis 10 ans ». Par Jacques Antoine, mai 1981. |
|
[B3] |
Micro-Systèmes N°56, p81-p83. Par Annick Kerherve, septembre 1985. |
|
[B4] |
Acoustique et Musique. Par E. Leipp, éditions Masson et Cie, 1971. |
|
[B5] |
Electronique Applications N°62, « La synthèse de la parole ». Par J. Trémolière, octobre 1988. |
|
[B6] |
Toute L'Electronique N°489, « La parole : analyse synthèse reconnaissance ». Par Eric Catier, décembre 1983. |
|
[B7] |
Thèse, « Etude de la paramétrisation du signal de parole à partir de représentation en ondelettes », chapitres 1 et 3, p3-39, p83-p119. Par Christophe Gérard, décembre 1995. |
|
[B8] |
Traitement du signal vol.7 N°4 spécial 1990 : Reconnais. de la parole. « Reconnaissance automatique de la parole : progrès et tendances ». Par Joseph Mariani, décembre 1990. |
|
[B9] |
IEEE, Signal Processing magazine, vol.13 N°5 ISSN 1053-5888. « A review of Large Vocabulary continuous speech Recognition ». Par Steve Young, septembre 1996. |
|
[B10] |
C.N.R.S. plus, « Langage humain et machine », p217-p230. Par R Carré, J.F. Dégremont, M. Gross, J.M. Pierrel et G.Sabah, 1991. |
|
[B11] |
Publication H1940, « Reconnaissance et compréhension automatique de la parole ». Par Jean-Paul Haton, 1982. |
|
[B12] |
Electronique N°23, p51-p58, « La reconnaissance vocale sort enfin du laboratoire » et « Un circuit intégré pour reconnaître la parole ». Par Hélène Trézéguet, décembre 1992. |
|
[B13] |
Probatoire C.N.A.M., « Le codage de la parole en temps réel, à faible débit binaire ». Par Ghislaine Marquis, février 1985. |
|
[B14] |
BT Technology Journal Vol.14 N°1 p112-p126, « The listening telephone - automating speech recognition over the PSTN ». Par Kevin Power, janvier 1996. |
|
[B15] |
Thèse, « Contribution à l'élaboration d'un système de reconnaissance de parole continu à grand vocabulaire », chapitre 1, p5-p29. Par Claire Waast, janvier 1994. |
|
[B16] |
Traitement Automatique des Langues, Vol.38 N°2,p7-p21. « Etat de l'art ». Par Jean-Marie Pierrel, 1997 |
|
[B17] |
IEEE ASSP Magazine. « An introduction to Hidden Markov Models », p3-p7. Par L.R. Rabiner et B.H. Juang, janvier 1986. |
|
[B18] |
EDN Europe. « Automatic speech recognition lets machines listen and comprehend », p73-p80. Par Stephen Kempainen, mars 1997. |
|
[B19] |
Byte, p97-p104. « Talking to machine ». Par Judith Markovitz, décembre 1995 |
|
[B20] |
Probatoire CNAM, « Analyse et synthèse de la parole ». Par Richard Boucheteau, avril 1989. |
|
[B21] |
Synthèse, reconnaissance de la parole. Par Marc Ferretti et François Cinare, éditions Editest, 1983 |
|
[B22 |
Thèse, « Décomposition d'un signal sur un ensemble de formes d'ondes élémentaires ». Par Christophe D’Allessandro. |
Retour
![]()